BA systems down globally
Discussion

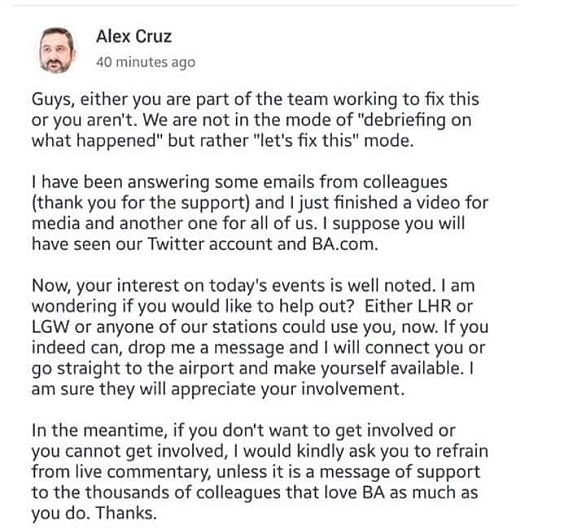
gothatway said:
Who on earth was that sent to ? It sounds really desperate - is he asking all trolley dollies to descend on the data centres ? That'll help, I'm sure.
I think he's asking for people to go to the airports to help. Which would suggest they are not. Which would suggest he's lost the respect of his employees. Mrs BC and I managed to fly to Washington with BA ( stands for Bloody Awful) yesterday. The worst part for us was that the BA app and website were still asking long haul passengers to arrive 3 hours before their flights. On arrival they had to wait outside in the rain until 90 minutes before their flight time.
jonny996 said:
I would say a proper run DC has diesel messured in days run time,
Hindsight is a wonderful thing.  This was during the height of the dot-com era when data centre resilience was still in its infancy.
This was during the height of the dot-com era when data centre resilience was still in its infancy.In this situation, seven days fuel supply would have kept the real flaw hidden, which was insufficient monitoring of the fuel consumption during the resilience testing. This situation did surface that flaw and allow it to be mitigated as set out above.
Resilience is always about balancing the risks, deciding were the budget is best spent, even when generous. I favour learning to be designed into governance processes.
Puggit said:
I think he's asking for people to go to the airports to help.
That's how I read it too. What sort of problem could it genuinely be if any old BA employee were able to help ?Hang on - I've got it ! They're addressing their power issue by installing loads of exercise bikes with generators attached ! That must be it.
Puggit said:
gothatway said:
Who on earth was that sent to ? It sounds really desperate - is he asking all trolley dollies to descend on the data centres ? That'll help, I'm sure.
I think he's asking for people to go to the airports to help. Which would suggest they are not. Which would suggest he's lost the respect of his employees. It's pretty typical when something major happens that people want to drag you away from fixing it, so you can tell them what you are doing to fix it.
anonymous said:
[redacted]
Find these hard to believe too. Again, it would be incompetence on an unprecedented scale. This isn't to say it could not possibly have happened. But if it did I could not imagine their third party supplier surviving and could easily see large organisations across the board rethinking where they have their services outsourced to.
Bashing the likes of TCS is fashionable, but the real fault doesn't lie with them. Just to be clear, I don't work for them, and I can't stand this lowest common denominator outsourcing - on the +side, picking up the pieces tends to keep me employed.
They picked up a load of systems that have probably been running for decades, some of it will be totally undocumented and totally "black box", other bits of it will have been built more recently out of whatever piece of modern architecture that took the designers fancy and will be similarly poorly documented and unsupportable.
So we seem to have a panicked rollout of security patches, security has got a bit of a high profile recently among the management types, so the order will have gone out "patch it ALL". Clearly the management types don't do patching (or even know what a patch is), and it will have been pushed down the chain to some junior bloke following badly written instructions. So at god knows o'clock in some drab office Chennai, some bloke will have been banging patches onto servers. This isn't nice virtualised stuff, there will be a lot of "on the metal", and even if it is VMs, no one invested in them, so it is cheaper to get some bloke at £20 aday to do some typing.
Boom. Actually it's not boom if the root cause is patching, it's a series of small failures, which is much, much worse. The problem is not recovering the systems - they probably did that very quickly. The problem is consistency of the underlying data. A simple example: say you've got a booking system and something that handles booked flights. They go down at different times. So they both wake up again and start double booking flights, or failing to process anything because bookings have vanished. Stick another 10 systems in the mix and you've got sphagetti that is really hard to untangle. In bad cases, you need 100 humans to "knife and fork " transactions through the stack.
So the blame doesn't lie with the junior guy pressing buttons. It lies in the design phase, and when it comes to massive legacy systems, the unwillingness to invest in fixing historical problems. The modern trend for everything going massively distributed compounds the issue. Designing for failure is really hard. Something that I have recently worked on had this as a core principle: components of the system can "wake up" and start processing. Dupes, missing data, bad data, it handles it. This takes money and time .... which most programmes aren't given.
They picked up a load of systems that have probably been running for decades, some of it will be totally undocumented and totally "black box", other bits of it will have been built more recently out of whatever piece of modern architecture that took the designers fancy and will be similarly poorly documented and unsupportable.
So we seem to have a panicked rollout of security patches, security has got a bit of a high profile recently among the management types, so the order will have gone out "patch it ALL". Clearly the management types don't do patching (or even know what a patch is), and it will have been pushed down the chain to some junior bloke following badly written instructions. So at god knows o'clock in some drab office Chennai, some bloke will have been banging patches onto servers. This isn't nice virtualised stuff, there will be a lot of "on the metal", and even if it is VMs, no one invested in them, so it is cheaper to get some bloke at £20 aday to do some typing.
Boom. Actually it's not boom if the root cause is patching, it's a series of small failures, which is much, much worse. The problem is not recovering the systems - they probably did that very quickly. The problem is consistency of the underlying data. A simple example: say you've got a booking system and something that handles booked flights. They go down at different times. So they both wake up again and start double booking flights, or failing to process anything because bookings have vanished. Stick another 10 systems in the mix and you've got sphagetti that is really hard to untangle. In bad cases, you need 100 humans to "knife and fork " transactions through the stack.
So the blame doesn't lie with the junior guy pressing buttons. It lies in the design phase, and when it comes to massive legacy systems, the unwillingness to invest in fixing historical problems. The modern trend for everything going massively distributed compounds the issue. Designing for failure is really hard. Something that I have recently worked on had this as a core principle: components of the system can "wake up" and start processing. Dupes, missing data, bad data, it handles it. This takes money and time .... which most programmes aren't given.
anonymous said:
[redacted]
I'm just curious, why you think India is any worse than remote staff in any other location in the world? I've worked extensively all over India (as well as in the US, Asia and throughout Europe) - and I have found IT colleagues in India to be just as skilled and capable IT professionals as anywhere else in the world. The problem is companies screw outsourcing suppliers down to the lowest possible price, which forces suppliers into heavily depending on automation and tooling and minimal staffing required to meet SLAs (and nothing more) in order to meet their cost-base.
IT geekiness aside, the situation looks much better today.
Terminal 5 seems to be operating close to normal; I took around 25 minutes to drop bags, hetvthepigh security and into the lounge.
There are plenty of staff on the ground and seem to be resolving issues with luggage and rebooking well.
Terminal 5 seems to be operating close to normal; I took around 25 minutes to drop bags, hetvthepigh security and into the lounge.
There are plenty of staff on the ground and seem to be resolving issues with luggage and rebooking well.
rxe said:
So the blame doesn't lie with the junior guy pressing buttons. It lies in the design phase, and when it comes to massive legacy systems, the unwillingness to invest in fixing historical problems. The modern trend for everything going massively distributed compounds the issue. Designing for failure is really hard. Something that I have recently worked on had this as a core principle: components of the system can "wake up" and start processing. Dupes, missing data, bad data, it handles it. This takes money and time .... which most programmes aren't given.
Absolutely. I have been accountable for large scale outsourcing, and this is critical, plus adequately budgeting for risk and including contingent costs right up front. It is also critical that there are adequate knowledgeable staff assigned by the IT staff and it is not simply handed off to the outsourcer. Adequate time for testing and a parallel runs are critical . I have no relationship with TCS other that having outsourced some systems to them. It was important to actually visit with the company at the location where the systems will be managed, ascertain that they are receiving clear and complete documentation and instructions, and to ensure that the two ways communications are properly set up.Further. inevitably there will be changes the business processes as this occurs and they need to be managed and documented properly.
Oh dear.
Some OOMPA LOOMPA at the register said:
Last night I sent British Airways a Freedom of Information request asking for the very same information.
Wonder what they will decide to respond with!
theregisterWonder what they will decide to respond with!
Gassing Station | News, Politics & Economics | Top of Page | What's New | My Stuff